Fixing the Web, Part II
Three Things #102: January 14, 2024

As I said last week when I introduced the topic, the web and content are broken in too many ways and I can’t cover the major ones in one week, or even in two. So here we are at part two. Of three. Or four. Or possibly more. The web is far too broken to ignore!
Thing #4: Search 🔎
“For a growing but not universal portion of the web and the world, we allow Google to determine what is important, relevant, and true.” - Siva Vaidhyanathan, The Googlization of Everything
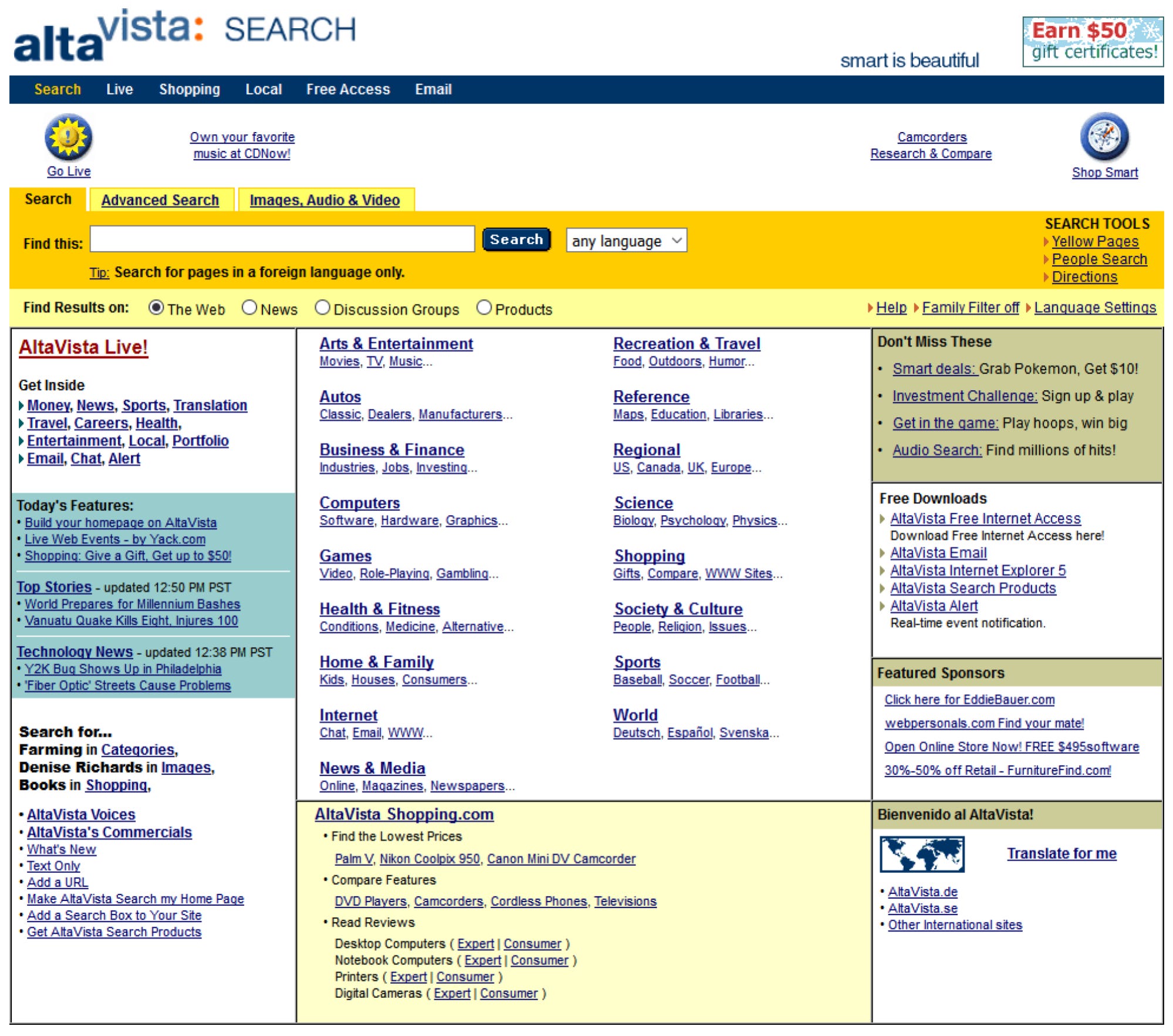
In the earliest days of the web search was impossible. Some of the earliest Internet applications including BBS, newsgroups, and gopher had search functionality but were limited to the scope of a single monolithic application running on a single server and provided no cross-domain search functionality. Then the web, the killer app of the Internet, came along and everything changed.
The web had many features lacking in these earlier protocols but arguably its most important killer feature was composability: the fact that any web page hosted on any server anywhere in the world could permissionlessly link to any other web page hosted on any other server anywhere in the world (sound familiar, my blockchain believooors?). But this cross-domain composability made search very difficult! How could you build a search tool that could index documents of many formats across such a decentralized network? I wasn’t in the room but I can imagine the investors, designers, and builders at the time debating this seemingly impossible problem.
We all know how the story ended: a first generation of “naive” web search engines such as AltaVista, Magellan, and Excite appeared and while they weren’t great they also were a lot better than nothing. Then Google came along a few years later with a much better, more efficient approach and some key insights and ate everyone’s lunch. The rest is history.
Except that this story is still being written. I’m not sure what your search experience has been lately but anecdotally it seems that mine is getting worse and worse. I’m having more and more trouble finding what I’m looking for and the various options available today including DuckDuckGo, Bing, Brave, and Google increasingly aren’t cutting it. I don’t know how much this is due to the simple monopoly/duopoly power of Google and Bing causing them to underinvest in improving their product, and how much it’s due to the increasing fragmentation of the web: walled gardens, paywalls, SPAs and dynamic content, social media and ephemeral content, fragmentation, and the appearance of much more structured data. In short the web is changing and search engines aren’t keeping up. But like so many things in technology today the network effects are quite strong and incumbents have such a head start that it’s very difficult to replace them, which is why we’re all still using Google in spite of a seriously subprime experience that’s actually getting worse. Search needs another paradigm shift.
Let’s start from the beginning. The web as we know it and as originally conceived is a set of publicly-accessible documents that link to one another using hyperlinks. That part of the web still works—you can still publish HTML pages with links—except when it doesn’t (see all of the examples I listed last week). A paywall is a great example. A web crawler will find plenty of links to documents that aren’t accessible to non-subscribers for which it can only index the metadata (e.g., document title, date, author, URL, first few words, etc.). In practice the web giants behind major search engines like Google have negotiated deals with big content providers and have special access to such content in order to index it, but it’s still not accessible to everyday users and such deals are barriers to entry for those wishing to launch competitive search engines. In other words they’re antithetical to the idea of an open web.
Blockchain and crypto offer another great example of how the original web paradigm is breaking. What’s a NFT? It’s certainly not a webpage. It’s more like an “immutable bookmark” or a “pointer”: a small piece of metadata with modifiable and transferable ownership. In fact, when you think about it abstractly a NFT is a superset of a web page, and of content more generally. What’s a web page if not a “bookmark” or “pointer” (or a set of these) to more substantial content including text and images?
The issue is that unlike a traditional web page the NFT doesn’t “live” anywhere. In the terms of the web it doesn’t have a permanent URI. The hyperlink and URL/URI system, just like email and the domain name system, is built around the old-fashioned notion of centralized, physical servers. This made sense in the seventies, eighties, and even nineties when companies, universities and other institutions had actual, physical servers, identified by domain names, that they operated and controlled, but it began to break down in the cloud era. Today NFTs aren’t unique in this respect. Most data that we access on the web doesn’t have a single home—it’s replicated and backed up globally for speed and redundancy—but we maintain the fiction with various tools like DNS-based load balancing. This abstraction breaks when two users attempting to access the “same” document in two different places and/or at two different times end up with totally different documents. (I wrote last week about how modern tools like content-addressable storage can fix this problem.)
But decentralized, immutable crypto applications and data like NFTs simply don’t fit into this model. As I said, a NFT simply doesn’t have a URI! A concrete example may be illustrative. My ENS (Ethereum Name Service) domain, lanechain.eth, is a NFT that I own. Its only URI is its ENS “token ID”, which is 5773164272799913803859189447880505702716. You can view information about it, including its current ownership and metadata, at https://etherscan.io/token/0x57f1887a8bf19b14fc0df6fd9b2acc9af147ea85?a=57731642727999138038591894478805057027166897266126960561158965344283323439476, but this is just the view of one centralized company (Etherscan) on the NFT (you can see another, different view on OpenSea; there are countless others). The only foolproof way to read this information without trusting someone else is to run your own Ethereum node—in which case, at the risk of repeating myself, there’s still no meaningful URI for this data!
In this respect crypto is the decentralized straw that broke the centralized web camel’s back, in the sense that old-fashioned notions of the web and of how to crawl, index, and search it will never map well to the new paradigm. The best Google can do is index the Etherscan or Opensea pages linked above. This isn’t an index of the actual NFT any more than a photo of a mountain is an actual mountain. We need crypto-native search engines that “speak crypto” and understand these important paradigms like ownership, tokenization, and decentralization, and underlying data structures like NFTs, keypair-based accounts, smart contracts, and blocks.
Search is a difficult problem and I don’t mean to suggest that these problems have easy solutions. I have no idea how to solve search for today’s web other than to suggest that we need a universal substrate where all assets are registered, and the NFT is the best tool we have for that today. The fact that we have many different chains, ecosystems, protocols, and standards doesn’t make it easy—but then all of these same problems existed in the original web era in the nineties when the first set of search engines emerged. The situation today is as head-scratchingly complex as the early web in the nineties. The solution then was standards and the creation of organizations like the IETF and the W3C, and I suspect the solution today will be similar. Interoperability is still mostly lacking in the crypto era—as one example, there are already dozens of competing NFT standards—and I strongly suspect that better interoperability is the right place to start looking for a solution.
In fact what we really want is probably not many search engines, per se, but rather a decentralized, distributed one (i.e., a protocol), where a network of indexers is responsible for finding, hosting, crawling, indexing, and operating the search engine. This is a complex protocol but similar, similarly complex ones already exist and it’s definitely doable. It’s a huge project but I’m sure something like this will eventually emerge. It feels inevitable.
Thing #5: Misinformation and Disinformation 📡
“AI makes things easy to copy and fake; crypto makes it hard again. This symbiosis is critical.” - Balaji Srinivasan
This thing is of course a huge topic by itself and it’s only grown in importance over time. It’s actually closely related to the fragmentation issue I discussed above. It’s grown in importance because a generation or two ago it wasn’t so hard to figure out what was going on in the world. Almost everyone read more or less the same books, listened to the same radio stations, watched the same TV stations and shows, and read the same newspapers. After all there just weren’t that many to choose from.
Let me be clear: I’m not suggesting that these sources of information always told the truth or always had the citizen’s best interest at heart—disinformation is of course not a new phenomenon and we’ve had our share of propaganda in this country too—but at the very least there was a semblance of social cohesiveness, even if it wasn’t always correct (“the USA is a proud country”; “gay people are degenerates”, “we must fight communism with democracy and capitalism”, etc.). I don’t have room here to tell the story of what happened since then—others have done that job much better than I could—but for better or worse thanks to social and political change coupled with powerful technology we now live in an ultra-fragmented age where people get their news and information and, indeed, their understanding of reality from a huge variety of places, some more trustworthy and some less (they all have their biases of course).
In recent decades social media made things much worse by making it easier for people to build, and indeed find themselves in, echo chambers where they’re surrounded by people who think and believe the same things they do. In retrospect it was inevitable that social media platforms would be hijacked and exploited for antisocial purposes by nefarious actors from North Korea to Russia to Donald Trump to Q-Anon to people who lie about vaccine effectiveness. Without casting the blame on any particular group or demographic, we can safely say that on average the ability of ordinary people to know what’s going on and what’s true fell massively during this period, as did their trust in previously respected institutions including the government, the courts, the UN and even the WHO. To be fair, understanding what’s true can be very difficult since the world is a complex place and it’s rapidly becoming more complex. Conspiracy theories are attractive because they’re simple and often less painful than accepting reality. A lack of trusted, ethical curators and thought leaders doesn’t help—or maybe it’s the opposite: the fact that there are a huge number of people who call themselves thought leaders.
As if all of that wasn’t bad enough, things got even worse in the past year due to the emergence of large language models and their ability to instantly churn out massive amounts of genuine-sounding information and content that’s at best loosely associated with the truth. This includes “deep fake” photos, videos, and voice recordings, which have actually already begun to sway politics and elections. It’s getting easier and easier to create convincing-sounding misinformation (which merely gets things wrong) and even disinformation (which does so intentionally with an ulterior motive) and it’s getting harder and harder to distinguish these from the truth. You could be forgiven for scrolling through images and stories from current conflicts like Russia-Ukraine and Israel-Gaza and genuinely not knowing what to believe, like I do. (At least having a healthy skepticism whenever encountering emotionally charged content is a good start.)
Fortunately we also have powerful new tools at our disposal with which to fight back, most prominently crypto (including both cryptography and the adjacent fields of blockchain and cryptocurrency). The use of cryptography to fight misinformation and disinformation has only just begun but I and others believe it will have a massive, positive impact over time. Machines can fake content but they cannot fake digital cryptographic signatures, at least not without stealing your private keys! If we can figure out how to get cryptographic keys into the hands of people, from journalists to photographers to government officials, and teach them how to keep those keys safe and how to use them (in the industry we refer to this as PKI or public key infrastructure)—and we’ve made a lot of progress along these lines lately—then in a few years it might be a bit easier to at least tell what information is genuine.
Thing #6: The Risks of Centralization 🏛️
“We cannot have a society in which if two people wish to communicate the only way that can happen is if it's financed by a third person who wishes to manipulate them.” - Jaron Lanier
As I’ve mentioned here a few times, the Internet as originally conceived of and designed was decentralized. Organizations including the universities, companies, and government institutes that served as the initial Internet nodes could publish content and users affiliated with those nodes could access the network via their node. (Having an email address such as user@domain.com used to mean the user had a real affiliation with the organization behind domain.com, rather than being merely a paid user!)
As we all know by now, however, decentralization is really hard. It makes sense for companies, universities, and government agencies to run servers but it doesn’t make sense for most ordinary people to run their own servers. Anecdotally, I tried running my own email server recently. In spite of having a lot of experience doing this (I used to professionally run several), I gave up after a few days. It’s just too difficult today.
It wasn’t always this way. In the beginning each Internet node hosted some content. Over time, however, service providers on the Internet have specialized. It turns out that today not every “host” is equally capable of or interested in hosting content. The tools to do so exist, as they have since the earliest days of the web: databases, web servers, CMS tools, etc. There are free, production-grade versions of all of these. But, as with running email servers, running web servers and hosting content more generally has also become very difficult.
Everything on the web these days is difficult because it’s gotten too complicated (more on this soon). Even setting up a simple blog from scratch is insanely complicated and would take days, not minutes or hours, to say nothing of the ongoing maintenance burden. It’s orders of magnitude easier to give your data to Squarespace, Substack, a blogging platform, or to a centralized social media network than it is to host content yourself. There are relatively straightforward options like Ghost and Jekyll but even these are mostly beyond the reach of users who aren’t tech savvy and don’t want to roll up their sleeves and write code and scripts.
As a result the entire modern Internet has become centralized, because it’s just easier and more efficient. Your email is centralized, captured as it has been by Google and Microsoft. Your identity is centralized, captured as it is by Google, Facebook, and a few others. Your data is mostly centralized, captured by—you guessed it—the same small group of companies. Think you own your data, your identity, your email? Think again. These companies can deplatform you with the click of a button, and they do so arbitrarily and without cause or accountability all the freaking time. Think you’re somehow special and that it can’t possibly happen to you? Think again.
Arbitrary deplatforming isn’t the only thing wrong with a centralized Internet. In an age of wokism and cancel culture, censorship is also a real problem. Democracy and society in general cannot function if ordinary people don’t have the freedom to speak their mind in public and be heard whether we agree with them or not; in other words, without Oliver Wendell Holmes Jr.’s famous “marketplace of ideas.” Yet, as Elon demonstrated last year when he took over Twitter, these same centralized, unaccountable, arbitrary platforms are increasingly being captured by extreme, harmful ideologies like “no mental discomfort” and by mainstream lies. If you don’t toe the party line, you’re likely to be canceled or at least severely censured, something we’ve seen happen to people from Elon to Joe Rogan to Donald Trump.
Then there’s the question of monetizing your content. Good luck doing this today on Youtube, Instagram, Tiktok, Twitch, or any other major, centralized platform. These platforms share only a tiny portion of their revenue with creators; as a result there’s a tiny set of people able to support themselves as creators on these platforms and an extremely long tail of people trying and failing to do so. As long as we continue to give our data and our content to these companies—as long as there are no viable alternatives—they’ll continue to exploit their monopolistic power and take advantage of us.
Okay, enough about what’s wrong and the current sorry state of affairs! What can and should we do about it? I believe that blockchain and cryptocurrency contain the keys to fixing these problems. It’s an idea that’s been talked about time and time again over the years but it’s also something that we’ve almost completely failed to deliver on (Elon has made far more progress with a freer, less woke X). This is understandable since shitcoin casinos are more attractive for investors, builders, and users alike, but I also believe that we’re moving into a new phase that will involve less casinos and more usable products and services—both because regulators are increasingly cracking down on the casinos, and because the latent demand for better software is enormous. Content is a great place to start! We finally have all the tools we need to build this sort of application, and it can be just as usable as the existing centralized ones.
More on some possible designs soon, once we finish reviewing all of the problems!